
上篇主要介绍和讨论了支持向量机。从最初的分类函数,通过最大化分类间隔,max(1/||w||),min(1/2||w||^2),凸二次规划,朗格朗日函数,对偶问题,一直到最后的SMO算法求解,都为寻找一个最优解。接着引入核函数将低维空间映射到高维特征空间,解决了非线性可分的情形。最后介绍了软间隔支持向量机,解决了outlier挤歪超平面的问题。本篇将讨论一个经典的统计学习算法–贝叶斯分类器。
#7、贝叶斯分类器
贝叶斯分类器是一种概率框架下的统计学习分类器,对分类任务而言,假设在相关概率都已知的情况下,贝叶斯分类器考虑如何基于这些概率为样本判定最优的类标。在开始介绍贝叶斯决策论之前,我们首先来回顾下概率论委员会常委–贝叶斯公式。
1.png
##7.1 贝叶斯决策论
若将上述定义中样本空间的划分Bi看做为类标,A看做为一个新的样本,则很容易将条件概率理解为样本A是类别Bi的概率。在机器学习训练模型的过程中,往往我们都试图去优化一个风险函数,因此在概率框架下我们也可以为贝叶斯定义“条件风险”(conditional risk)。
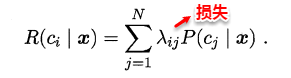
2.png
我们的任务就是寻找一个判定准则最小化所有样本的条件风险总和,因此就有了贝叶斯判定准则(Bayes decision rule):为最小化总体风险,只需在每个样本上选择那个使得条件风险最小的类标。
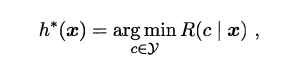
3.png
若损失函数λ取0-1损失,则有:
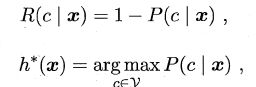
4.png
即对于每个样本x,选择其后验概率P(c | x)最大所对应的类标,能使得总体风险函数最小,从而将原问题转化为估计后验概率P(c | x)。一般这里有两种策略来对后验概率进行估计:
* 判别式模型:直接对 P(c | x)进行建模求解。例我们前面所介绍的决策树、神经网络、SVM都是属于判别式模型。
* 生成式模型:通过先对联合分布P(x,c)建模,从而进一步求解 P(c | x)。
贝叶斯分类器就属于生成式模型,基于贝叶斯公式对后验概率P(c | x) 进行一项神奇的变换,巴拉拉能量…. P(c | x)变身:
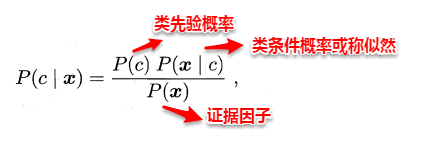
5.png