上篇主要介绍和讨论了线性模型。首先从最简单的最小二乘法开始,讨论输入属性有一个和多个的情形,接着通过广义线性模型延伸开来,将预测连续值的回归问题转化为分类问题,从而引入了对数几率回归,最后线性判别分析LDA将样本点进行投影,多分类问题实质上通过划分的方法转化为多个二分类问题进行求解。本篇将讨论另一种被广泛使用的分类算法–决策树(Decision Tree)。
#4、决策树
##4.1 决策树基本概念
顾名思义,决策树是基于树结构来进行决策的,在网上看到一个例子十分有趣,放在这里正好合适。现想象一位捉急的母亲想要给自己的女娃介绍一个男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
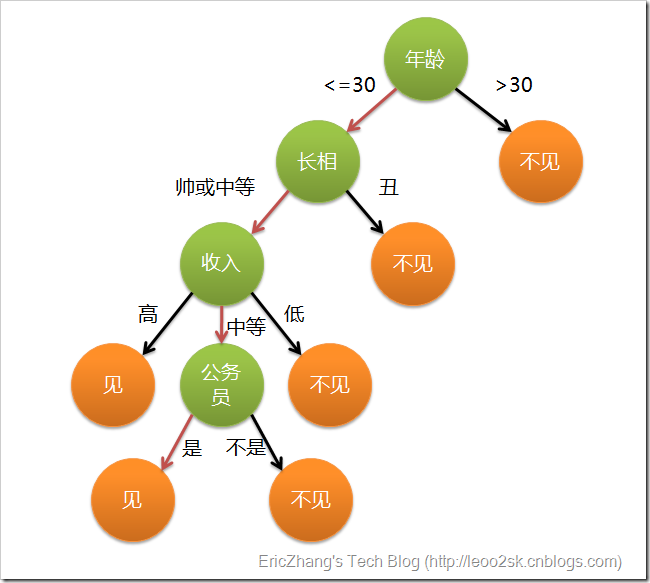
这个女孩的挑剔过程就是一个典型的决策树,即相当于通过年龄、长相、收入和是否公务员将男童鞋分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么使用下图就能很好地表示女孩的决策逻辑(即一颗决策树)。
1.png
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。一般一颗决策树包含:一个根节点、若干个内部节点和若干个叶子节点,易知:
* 每个非叶节点表示一个特征属性测试。
* 每个分支代表这个特征属性在某个值域上的输出。
* 每个叶子节点存放一个类别。
* 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。
##4.2 决策树的构造
决策树的构造是一个递归的过程,有三种情形会导致递归返回:(1) 当前结点包含的样本全属于同一类别,这时直接将该节点标记为叶节点,并设为相应的类别;(2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分,这时将该节点标记为叶节点,并将其类别设为该节点所含样本最多的类别;(3) 当前结点包含的样本集合为空,不能划分,这时也将该节点标记为叶节点,并将其类别设为父节点中所含样本最多的类别。算法的基本流程如下图所示:

2.png
可以看出:决策树学习的关键在于如何选择划分属性,不同的划分属性得出不同的分支结构,从而影响整颗决策树的性能。属性划分的目标是让各个划分出来的子节点尽可能地“纯”,即属于同一类别。因此下面便是介绍量化纯度的具体方法,决策树最常用的算法有三种:ID3,C4.5和CART。
###4.2.1 ID3算法
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:
