
本篇主要是对第二章剩余知识的理解,包括:性能度量、比较检验和偏差与方差。在上一篇中,我们解决了评估学习器泛化性能的方法,即用测试集的“测试误差”作为“泛化误差”的近似,当我们划分好训练/测试集后,那如何计算“测试误差”呢?这就是性能度量,例如:均方差,错误率等,即“测试误差”的一个评价标准。有了评估方法和性能度量,就可以计算出学习器的“测试误差”,但由于“测试误差”受到很多因素的影响,例如:算法随机性或测试集本身的选择,那如何对两个或多个学习器的性能度量结果做比较呢?这就是比较检验。最后偏差与方差是解释学习器泛化性能的一种重要工具。写到后面发现冗长之后读起来十分没有快感,故本篇主要知识点为性能度量。
2.5 性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。本节除2.5.1外,其它主要介绍分类模型的性能度量。
2.5.1 最常见的性能度量
在回归任务中,即预测连续值的问题,最常用的性能度量是“均方误差”(mean squared error),很多的经典算法都是采用了MSE作为评价函数,想必大家都十分熟悉。
1.png
在分类任务中,即预测离散值的问题,最常用的是错误率和精度,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,易知:错误率+精度=1。
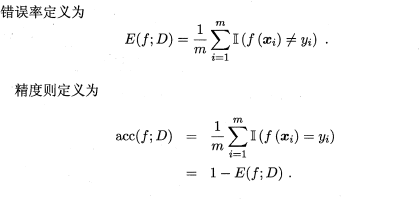
2.png

3.png
2.5.2 查准率/查全率/F1
错误率和精度虽然常用,但不能满足所有的需求,例如:在推荐系统中,我们只关心推送给用户的内容用户是否感兴趣(即查准率),或者说所有用户感兴趣的内容我们推送出来了多少(即查全率)。因此,使用查准/查全率更适合描述这类问题。对于二分类问题,分类结果混淆矩阵与查准/查全率定义如下:

4.png
初次接触时,FN与FP很难正确的理解,按照惯性思维容易把FN理解成:False->Negtive,即将错的预测为错的,这样FN和TN就反了,后来找到一张图,描述得很详细,为方便理解,把这张图也贴在了下边:
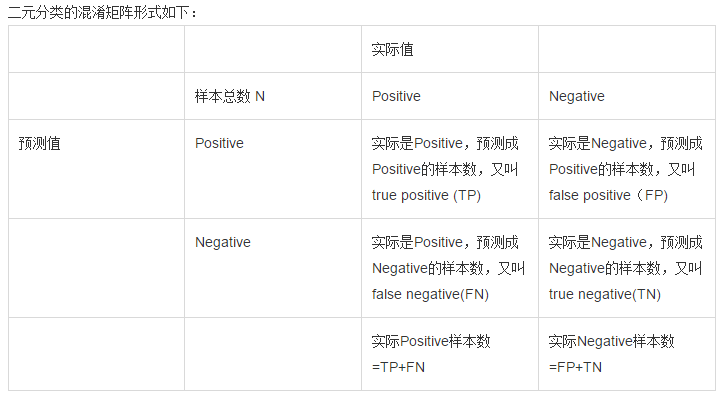
5.png
正如天下没有免费的午餐,查准率和查全率是一对矛盾的度量。例如我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,查全率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样查准率就很低了。