上篇主要介绍了半监督学习,首先从如何利用未标记样本所蕴含的分布信息出发,引入了半监督学习的基本概念,即训练数据同时包含有标记样本和未标记样本的学习方法;接着分别介绍了几种常见的半监督学习方法:生成式方法基于对数据分布的假设,利用未标记样本隐含的分布信息,使得对模型参数的估计更加准确;TSVM给未标记样本赋予伪标记,并通过不断调整易出错样本的标记得到最终输出;基于分歧的方法结合了集成学习的思想,通过多个学习器在不同视图上的协作,有效利用了未标记样本数据 ;最后半监督聚类则是借助已有的监督信息来辅助聚类的过程,带约束k-均值算法需检测当前样本划分是否满足约束关系,带标记k-均值算法则利用有标记样本指定初始类中心。本篇将讨论一种基于图的学习算法–概率图模型。
#15、概率图模型
现在再来谈谈机器学习的核心价值观,可以更通俗地理解为:根据一些已观察到的证据来推断未知,更具哲学性地可以阐述为:未来的发展总是遵循着历史的规律。其中基于概率的模型将学习任务归结为计算变量的概率分布,正如之前已经提到的:生成式模型先对联合分布进行建模,从而再来求解后验概率,例如:贝叶斯分类器先对联合分布进行最大似然估计,从而便可以计算类条件概率;判别式模型则是直接对条件分布进行建模。
概率图模型(probabilistic graphical model)是一类用图结构来表达各属性之间相关关系的概率模型,一般而言:图中的一个结点表示一个或一组随机变量,结点之间的边则表示变量间的相关关系,从而形成了一张“变量关系图”。若使用有向的边来表达变量之间的依赖关系,这样的有向关系图称为贝叶斯网(Bayesian nerwork)或有向图模型;若使用无向边,则称为马尔可夫网(Markov network)或无向图模型。
##15.1 隐马尔可夫模型(HMM)
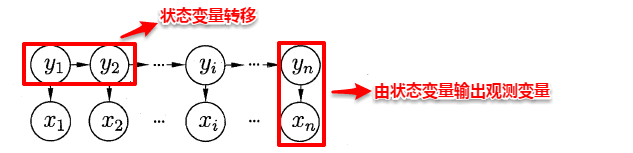
隐马尔可夫模型(Hidden Markov Model,简称HMM)是结构最简单的一种贝叶斯网,在语音识别与自然语言处理领域上有着广泛的应用。HMM中的变量分为两组:状态变量与观测变量,其中状态变量一般是未知的,因此又称为“隐变量”,观测变量则是已知的输出值。在隐马尔可夫模型中,变量之间的依赖关系遵循如下两个规则:
- 观测变量的取值仅依赖于状态变量; 2. 下一个状态的取值仅依赖于当前状态,通俗来讲:现在决定未来,未来与过去无关,这就是著名的马尔可夫性。
iwYPmR.png
基于上述变量之间的依赖关系,我们很容易写出隐马尔可夫模型中所有变量的联合概率分布:
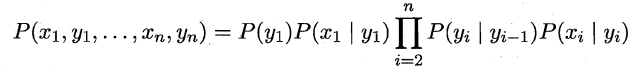
iwY9X9.png
易知:欲确定一个HMM模型需要以下三组参数:

iwYi01.png
当确定了一个HMM模型的三个参数后,便按照下面的规则来生成观测值序列:

iwYFTx.png
在实际应用中,HMM模型的发力点主要体现在下述三个问题上:
