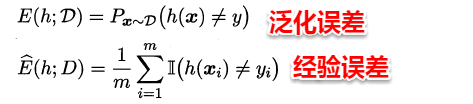
上篇主要介绍了常用的特征选择方法及稀疏学习。首先从相关/无关特征出发引出了特征选择的基本概念,接着分别介绍了子集搜索与评价、过滤式、包裹式以及嵌入式四种类型的特征选择方法。子集搜索与评价使用的是一种优中生优的贪婪算法,即每次从候选特征子集中选出最优子集;过滤式方法计算一个相关统计量来评判特征的重要程度;包裹式方法将学习器作为特征选择的评价准则;嵌入式方法则是通过L1正则项将特征选择融入到学习器参数优化的过程中。最后介绍了稀疏表示与压缩感知的核心思想:稀疏表示利用稀疏矩阵的优良性质,试图通过某种方法找到原始稠密矩阵的合适稀疏表示;压缩感知则试图利用可稀疏表示的欠采样信息来恢复全部信息。本篇将讨论一种为机器学习提供理论保证的学习方法–计算学习理论。
#13、计算学习理论
计算学习理论(computational learning theory)是通过“计算”来研究机器学习的理论,简而言之,其目的是分析学习任务的本质,例如:在什么条件下可进行有效的学习,需要多少训练样本能获得较好的精度等,从而为机器学习算法提供理论保证。
首先我们回归初心,再来谈谈经验误差和泛化误差。假设给定训练集D,其中所有的训练样本都服从一个未知的分布T,且它们都是在总体分布T中独立采样得到,即独立同分布(independent and identically distributed,i.i.d.),在《贝叶斯分类器》中我们已经提到:独立同分布是很多统计学习算法的基础假设,例如最大似然法,贝叶斯分类器,高斯混合聚类等,简单来理解独立同分布:每个样本都是从总体分布中独立采样得到,而没有拖泥带水。例如现在要进行问卷调查,要从总体人群中随机采样,看到一个美女你高兴地走过去,结果她男票突然冒了出来,说道:you jump,i jump,于是你本来只想调查一个人结果被强行撒了一把狗粮得到两份问卷,这样这两份问卷就不能称为独立同分布了,因为它们的出现具有强相关性。
回归正题,泛化误差指的是学习器在总体上的预测误差,经验误差则是学习器在某个特定数据集D上的预测误差。在实际问题中,往往我们并不能得到总体且数据集D是通过独立同分布采样得到的,因此我们常常使用经验误差作为泛化误差的近似。
1.png
##13.1 PAC学习
在高中课本中,我们将函数定义为:从自变量到因变量的一种映射;对于机器学习算法,学习器也正是为了寻找合适的映射规则,即如何从条件属性得到目标属性。从样本空间到标记空间存在着很多的映射,我们将每个映射称之为概念(concept),定义:
若概念c对任何样本x满足c(x)=y,则称c为目标概念,即最理想的映射,所有的目标概念构成的集合称为“概念类”; 给定学习算法,它所有可能映射/概念的集合称为“假设空间”,其中单个的概念称为“假设”(hypothesis); 若一个算法的假设空间包含目标概念,则称该数据集对该算法是可分(separable)的,亦称一致(consistent)的; 若一个算法的假设空间不包含目标概念,则称该数据集对该算法是不可分(non-separable)的,或称不一致(non-consistent)的。
举个简单的例子:对于非线性分布的数据集,若使用一个线性分类器,则该线性分类器对应的假设空间就是空间中所有可能的超平面,显然假设空间不包含该数据集的目标概念,所以称数据集对该学习器是不可分的。给定一个数据集D,我们希望模型学得的假设h尽可能地与目标概念一致,这便是概率近似正确 (Probably Approximately Correct,简称PAC)的来源,即以较大的概率学得模型满足误差的预设上限。

2.png

3.png

4.png

5.png
上述关于PAC的几个定义层层相扣:定义12.1表达的是对于某种学习算法,如果能以一个置信度学得假设满足泛化误差的预设上限,则称该算法能PAC辨识概念类,即该算法的输出假设已经十分地逼近目标概念。定义12.2则将样本数量考虑进来,当样本超过一定数量时,学习算法总是能PAC辨识概念类,则称概念类为PAC可学习的。定义12.3将学习器运行时间也考虑进来,若运行时间为多项式时间,则称PAC学习算法。