
上篇主要介绍了经典的降维方法与度量学习,首先从“维数灾难”导致的样本稀疏以及距离难计算两大难题出发,引出了降维的概念,即通过某种数学变换将原始高维空间转变到一个低维的子空间,接着分别介绍了kNN、MDS、PCA、KPCA以及两种经典的流形学习方法,k近邻算法的核心在于k值的选取以及距离的度量,MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持,主成分分析试图找到一个低维超平面来表出原空间样本点,核化主成分分析先将样本点映射到高维空间,再在高维空间中使用线性降维的方法,从而解决了原空间样本非线性分布的情形,基于流形学习的降维则是一种“邻域保持”的思想,最后度量学习试图去学习出一个距离度量来等效降维的效果。本篇将讨论另一种常用方法–特征选择与稀疏学习。
#12、特征选择与稀疏学习
最近在看论文的过程中,发现对于数据集行和列的叫法颇有不同,故在介绍本篇之前,决定先将最常用的术语罗列一二,以后再见到了不管它脚扑朔还是眼迷离就能一眼识破真身了~对于数据集中的一个对象及组成对象的零件元素:
统计学家常称它们为观测(observation)和变量(variable); 数据库分析师则称其为记录(record)和字段(field); 数据挖掘/机器学习学科的研究者则习惯把它们叫做样本/示例(example/instance)和属性/特征(attribute/feature)。
回归正题,在机器学习中特征选择是一个重要的“数据预处理”(data preprocessing)过程,即试图从数据集的所有特征中挑选出与当前学习任务相关的特征子集,接着再利用数据子集来训练学习器;稀疏学习则是围绕着稀疏矩阵的优良性质,来完成相应的学习任务。
##12.1 子集搜索与评价
一般地,我们可以用很多属性/特征来描述一个示例,例如对于一个人可以用性别、身高、体重、年龄、学历、专业、是否吃货等属性来描述,那现在想要训练出一个学习器来预测人的收入。根据生活经验易知:并不是所有的特征都与学习任务相关,例如年龄/学历/专业可能很大程度上影响了收入,身高/体重这些外貌属性也有较小的可能性影响收入,但像是否是一个地地道道的吃货这种属性就八杆子打不着了。因此我们只需要那些与学习任务紧密相关的特征,特征选择便是从给定的特征集合中选出相关特征子集的过程。
与上篇中降维技术有着异曲同工之处的是,特征选择也可以有效地解决维数灾难的难题。具体而言:降维从一定程度起到了提炼优质低维属性和降噪的效果,特征选择则是直接剔除那些与学习任务无关的属性而选择出最佳特征子集。若直接遍历所有特征子集,显然当维数过多时遭遇指数爆炸就行不通了;若采取从候选特征子集中不断迭代生成更优候选子集的方法,则时间复杂度大大减小。这时就涉及到了两个关键环节:1.如何生成候选子集;2.如何评价候选子集的好坏,这便是早期特征选择的常用方法。书本上介绍了贪心算法,分为三种策略:
前向搜索:初始将每个特征当做一个候选特征子集,然后从当前所有的候选子集中选择出最佳的特征子集;接着在上一轮选出的特征子集中添加一个新的特征,同样地选出最佳特征子集;最后直至选不出比上一轮更好的特征子集。 后向搜索:初始将所有特征作为一个候选特征子集;接着尝试去掉上一轮特征子集中的一个特征并选出当前最优的特征子集;最后直到选不出比上一轮更好的特征子集。 双向搜索:将前向搜索与后向搜索结合起来,即在每一轮中既有添加操作也有剔除操作。
对于特征子集的评价,书中给出了一些想法及基于信息熵的方法。假设数据集的属性皆为离散属性,这样给定一个特征子集,便可以通过这个特征子集的取值将数据集合划分为V个子集。例如:A1={男,女},A2={本科,硕士}就可以将原数据集划分为2*2=4个子集,其中每个子集的取值完全相同。这时我们就可以像决策树选择划分属性那样,通过计算信息增益来评价该属性子集的好坏。
1.png
此时,信息增益越大表示该属性子集包含有助于分类的特征越多,使用上述这种子集搜索与子集评价相结合的机制,便可以得到特征选择方法。值得一提的是若将前向搜索策略与信息增益结合在一起,与前面我们讲到的ID3决策树十分地相似。事实上,决策树也可以用于特征选择,树节点划分属性组成的集合便是选择出的特征子集。
##12.2 过滤式选择(Relief)
过滤式方法是一种将特征选择与学习器训练相分离的特征选择技术,即首先将相关特征挑选出来,再使用选择出的数据子集来训练学习器。Relief是其中著名的代表性算法,它使用一个“相关统计量”来度量特征的重要性,该统计量是一个向量,其中每个分量代表着相应特征的重要性,因此我们最终可以根据这个统计量各个分量的大小来选择出合适的特征子集。
易知Relief算法的核心在于如何计算出该相关统计量。对于数据集中的每个样例xi,Relief首先找出与xi同类别的最近邻与不同类别的最近邻,分别称为猜中近邻(near-hit)与猜错近邻(near-miss),接着便可以分别计算出相关统计量中的每个分量。对于j分量:
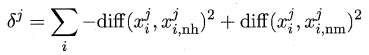
2.png
直观上理解:对于猜中近邻,两者j属性的距离越小越好,对于猜错近邻,j属性距离越大越好。更一般地,若xi为离散属性,diff取海明距离,即相同取0,不同取1;若xi为连续属性,则diff为曼哈顿距离,即取差的绝对值。分别计算每个分量,最终取平均便得到了整个相关统计量。
标准的Relief算法只用于二分类问题,后续产生的拓展变体Relief-F则解决了多分类问题。对于j分量,新的计算公式如下: