上篇主要介绍了鼎鼎大名的EM算法,从算法思想到数学公式推导(边际似然引入隐变量,Jensen不等式简化求导),EM算法实际上可以理解为一种坐标下降法,首先固定一个变量,接着求另外变量的最优解,通过其优美的“两步走”策略能较好地估计隐变量的值。本篇将继续讨论下一类经典算法–集成学习。
#9、集成学习
顾名思义,集成学习(ensemble learning)指的是将多个学习器进行有效地结合,组建一个“学习器委员会”,其中每个学习器担任委员会成员并行使投票表决权,使得委员会最后的决定更能够四方造福普度众生…,即其泛化性能要能优于其中任何一个学习器。
##9.1 个体与集成
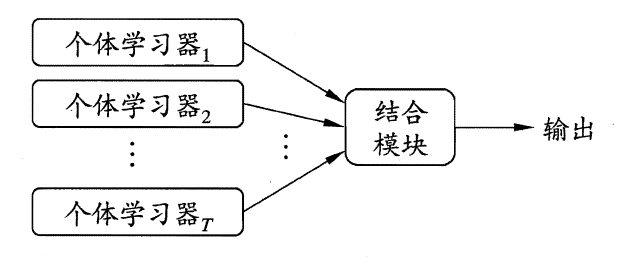
集成学习的基本结构为:先产生一组个体学习器,再使用某种策略将它们结合在一起。集成模型如下图所示:
1.png
在上图的集成模型中,若个体学习器都属于同一类别,例如都是决策树或都是神经网络,则称该集成为同质的(homogeneous);若个体学习器包含多种类型的学习算法,例如既有决策树又有神经网络,则称该集成为异质的(heterogenous)。
同质集成:个体学习器称为“基学习器”(base learner),对应的学习算法为“基学习算法”(base learning algorithm)。 异质集成:个体学习器称为“组件学习器”(component learner)或直称为“个体学习器”。
上面我们已经提到要让集成起来的泛化性能比单个学习器都要好,虽说团结力量大但也有木桶短板理论调皮捣蛋,那如何做到呢?这就引出了集成学习的两个重要概念:准确性和多样性(diversity)。准确性指的是个体学习器不能太差,要有一定的准确度;多样性则是个体学习器之间的输出要具有差异性。通过下面的这三个例子可以很容易看出这一点,准确度较高,差异度也较高,可以较好地提升集成性能。

2.png
现在考虑二分类的简单情形,假设基分类器之间相互独立(能提供较高的差异度),且错误率相等为 ε,则可以将集成器的预测看做一个伯努利实验,易知当所有基分类器中不足一半预测正确的情况下,集成器预测错误,所以集成器的错误率可以计算为:

3.png
此时,集成器错误率随着基分类器的个数的增加呈指数下降,但前提是基分类器之间相互独立,在实际情形中显然是不可能的,假设训练有A和B两个分类器,对于某个测试样本,显然满足:P(A=1 | B=1)> P(A=1),因为A和B为了解决相同的问题而训练,因此在预测新样本时存在着很大的联系。因此,个体学习器的“准确性”和“差异性”本身就是一对矛盾的变量,准确性高意味着牺牲多样性,所以产生“好而不同”的个体学习器正是集成学习研究的核心。现阶段有三种主流的集成学习方法:Boosting、Bagging以及随机森林(Random Forest),接下来将进行逐一介绍。
##9.2 Boosting
Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting族算法最著名、使用最为广泛的就是AdaBoost,因此下面主要是对AdaBoost算法进行介绍。AdaBoost使用的是指数损失函数,因此AdaBoost的权值与样本分布的更新都是围绕着最小化指数损失函数进行的。看到这里回想一下之前的机器学习算法,不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数:如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是log-Loss,那就是Logistic Regression了。
定义基学习器的集成为加权结合,则有: